
Adding asset metadata
In Kili, you can add extra information to an asset by using asset metadata. This can be information on document language, custom quality metrics, agreement metrics and so on that you can use, for example when using Kili's advanced filters or for Optical Character Recognition.
Adding metadata to assets
You can add metadata to your assets using our Python SDK in two ways:
- When uploading assets: include metadata directly using the
append_many_to_datasetmethod. - When updating existing assets: use the
add_metadatamethod to attach or modify metadata after upload.
For implementation details and examples, refer to our Python API documentation.
Configuring Metadata Properties
Asset metadata are included in label exports and can be used to enhance project workflows in two ways:
- As filters in the Project queue and Explore interface
- As contextual information visible to labelers and reviewers during annotation
You can define how each metadata field should behave using the Python SDK via the update_properties_in_project method.
This allows you to control whether a field is visible in the labeling interface, filterable, and its data type.
For full implementation details and examples, refer to our Python SDK documentation.
Using Asset Metadata in Filters
Asset metadata can be a powerful way to filter and organize your assets. To learn more about advanced filtering, see Filtering assets.
By default, metadata values are treated as string, but you can set the type to numberor date if you prefer using a slider or a date picker to filter numeric/date values.
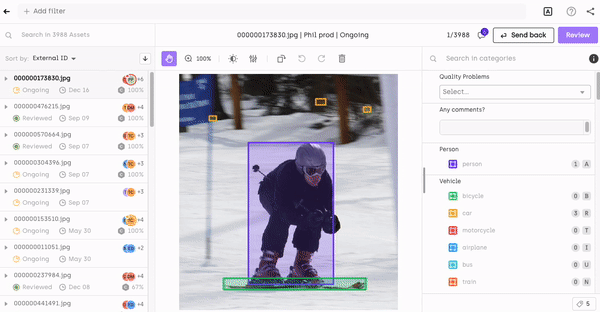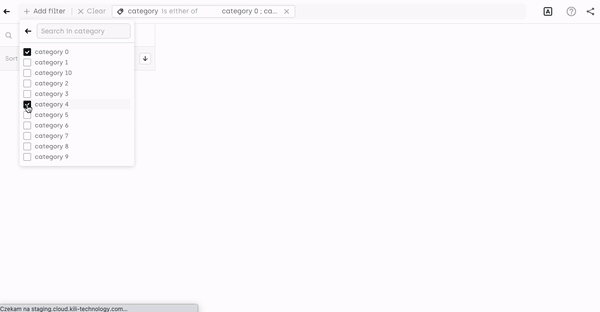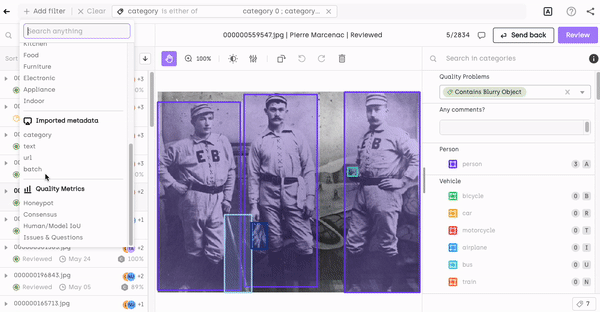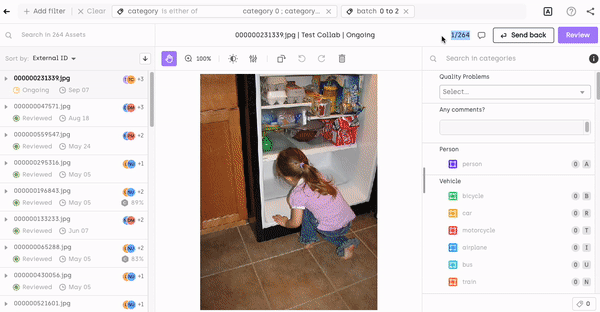
Filtering by asset metadata
Displaying Metadata to Labelers and Reviewers
Certain reserved metadata keys can be used to display important information at the top of the metadata panel in the labeling interface. These include:
imageUrltexturl
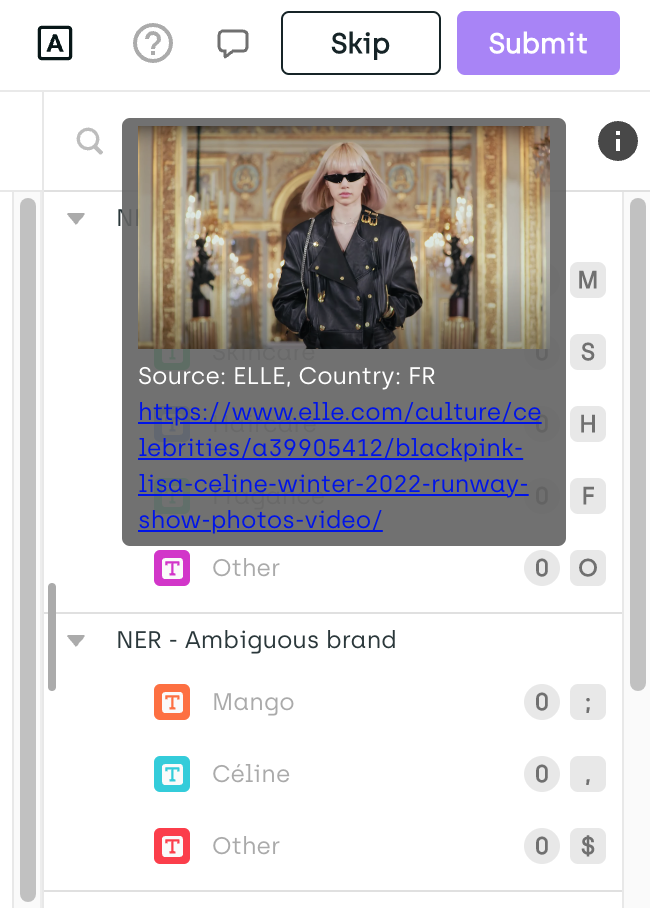
If you’re using a cloud service to host the images used for asset metadata, check if your cloud CORS settings are configured properly. If the CORS settings are misconfigured, the images will not show on screen.
Custom metadata provided as key-value pairs will be displayed in a table within the metadata panel, making it easy for project members to reference additional context during annotation.
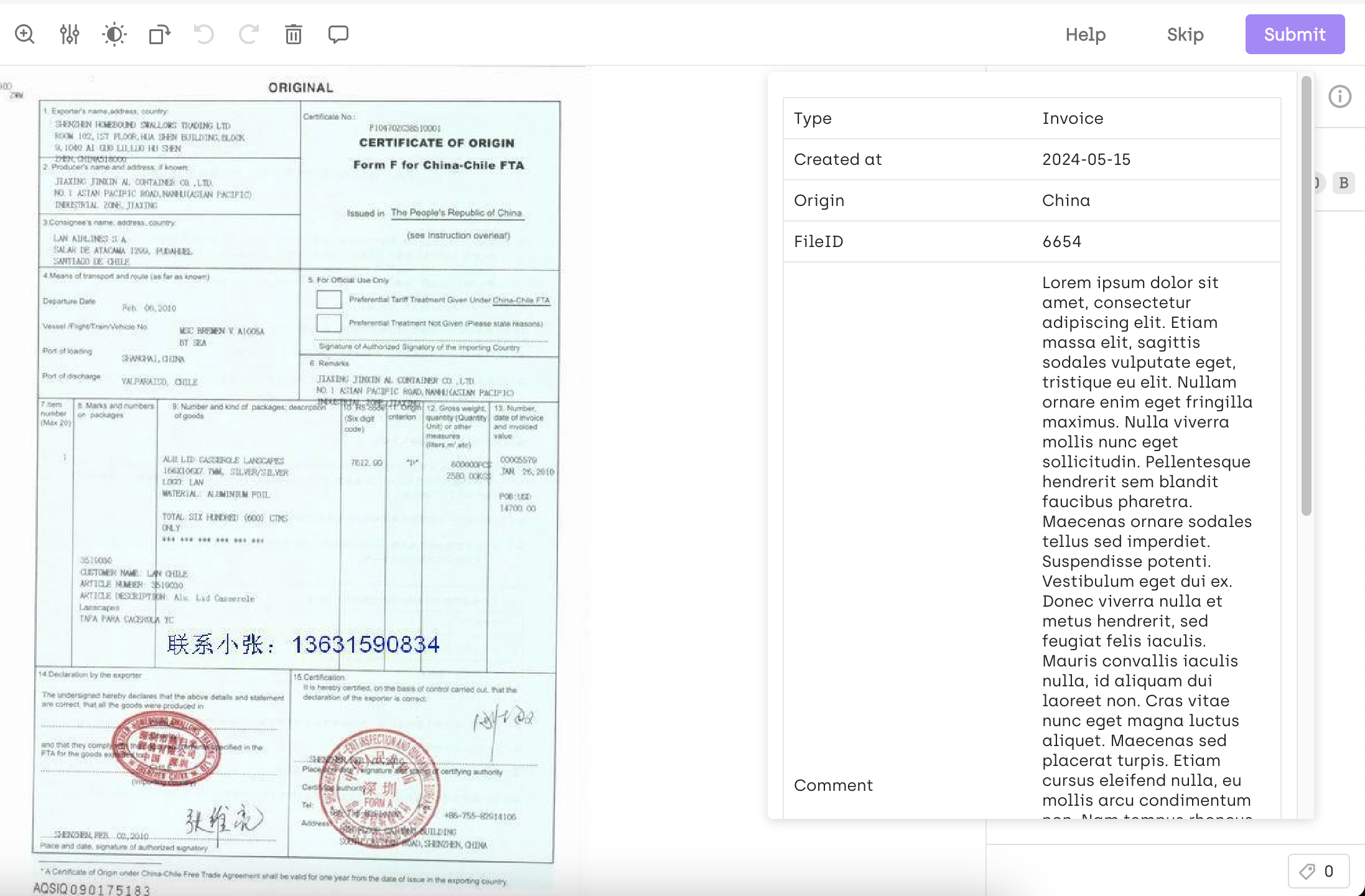
Adding OCR metadata to assets
For examples of how to import OCR metadata, refer to:
- Importing OCR metadata through API when creating image assets
- Importing OCR metadata through API when updating image assets
- Importing OCR metadata for pdf documents
Importing OCR metadata through Kili SDK when creating image assets
json_metadata = {
"fullTextAnnotation": { "pages": [{ "height": 914, "width": 813 }] },
"textAnnotations": [
{
"description": "7SB75",
"boundingPoly": {
"vertices": [
{ "x": 536, "y": 259 },
{ "x": 529, "y": 514 },
{ "x": 449, "y": 512 },
{ "x": 456, "y": 257 }
]
}
},
...
]
}
kili.append_many_to_dataset(
project_id='xxx',
content_array=['url'],
external_id_array=['A document'],
json_metadata_array=[json_metadata]
)Importing OCR metadata through API when updating image assets
json_metadata = {
"fullTextAnnotation": { "pages": [{ "height": 914, "width": 813 }] },
"textAnnotations": [
{
"description": "7SB75",
"boundingPoly": {
"vertices": [
{ "x": 536, "y": 259 },
{ "x": 529, "y": 514 },
{ "x": 449, "y": 512 },
{ "x": 456, "y": 257 }
]
}
},
...
]
}
# OR
json_metadata = {
"ocrMetadata": "url_to_json_metadata_object_with_keys_fullTextAnnotation_and_textAnnotations",
"key": "value", # Other metadata fields
"key2": "value3" # Other metadata fields
}
# OR
json_metadata = "url_to_json_metadata_object_with_keys_fullTextAnnotation_and_textAnnotations"
kili.update_properties_in_assets(
asset_ids=['asset_id'],
json_metadatas=[json_metadata]
)Importing OCR metadata for PDF documents
The metadata format for uploading OCR to PDF documents is similar to the one of images. Here is an example:
json_metadata = {
"fullTextAnnotation": {
"0": { "pages": [{ "height": 914, "width": 813 }] },
"1": { "pages": [{ "height": 914, "width": 813 }] }
},
"textAnnotations": {
"0": [
{
"description": "7SB75",
"boundingPoly": {
"vertices": [
{ "x": 536, "y": 259 },
{ "x": 529, "y": 514 },
{ "x": 449, "y": 512 },
{ "x": 456, "y": 257 }
]
}
}
],
"1": [
{
"description": "XHE",
"boundingPoly": {
"vertices": [
{ "x": 536, "y": 259 },
{ "x": 529, "y": 514 },
{ "x": 449, "y": 512 },
{ "x": 456, "y": 257 }
]
}
}
]
}
}
kili.update_properties_in_assets(
asset_ids=['asset_id'],
json_metadatas=[json_metadata]
)As you can see, fullTextAnnotation and textAnnotations are now objects whose keys are the index of the page where the metadata should apply ("0" for the first page, "1" for the second page, etc.)
Learn more
For an end-to-end example of how to programmatically add asset metadata to a project using Kili's Python SDK, refer to our Importing assets and metadata tutorial.
Updated 8 months ago